Data & AI Summit 2023

This year I got to attend Databricks DATA + AI Summit 2023 in San Francisco and it felt like my first time in Disney. I will tell you some of the reasons why I enjoyed it so much and why you should get interested and involved with it from now on.
Context
I have been closely following Databricks’ technology, virtually attending the Summit and organizing several Apache Spark meetups in Bogotá and in México City for a few years. Why? To stay tuned with this incredible technology that is conquering the DATA + AI landscape world wide.
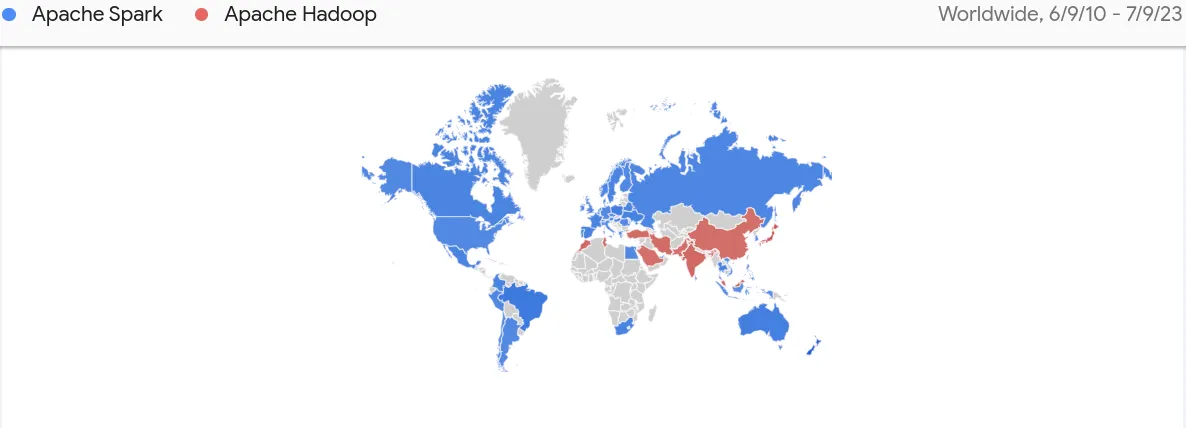 Apache Spark vs Apache Hadoop Compared breakdown by region by Google Trends World Wide
Apache Spark vs Apache Hadoop Compared breakdown by region by Google Trends World Wide
Globally the interest in this technology started exploding back in 2014 since Apache Spark won the battle on data speed processing with Apache Hadoop in Daytona Gray Sort 100TB Benchmark. You can see the trend in the following Google Trends charts.
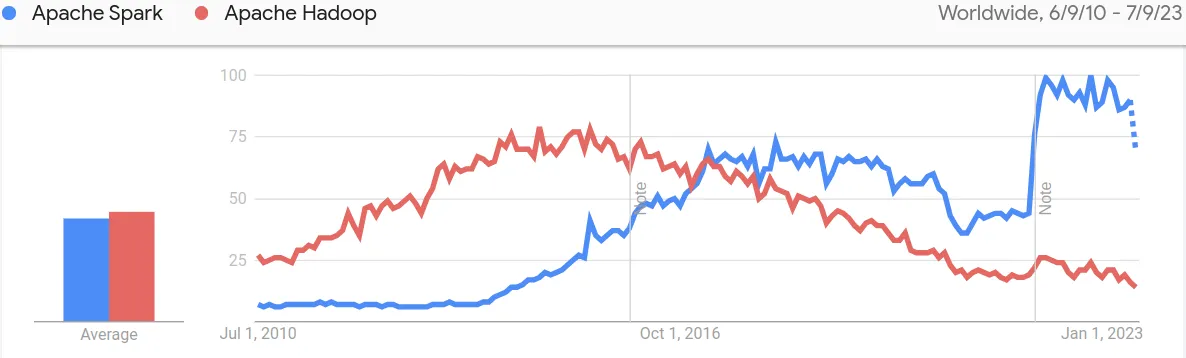 Apache Spark vs Apache Hadoop Interest over Time by Google Trends World Wide
Apache Spark vs Apache Hadoop Interest over Time by Google Trends World Wide
Engineering (Inner Sourcing vs Open Sourcing)
Databricks engineers are the original creators and have led the development not only of Apache Spark but also some of the world’s most popular open source data technologies such as Delta Lake, MLFlow, Spark, Redash and also support many other OSS projects.
 Spark, MLFlow, Delta Lake
Spark, MLFlow, Delta Lake
These highly technical geniuses didn’t start working having revenue in mind. They were aiming to solve tough problems for the DATA + AI community and this led them to create great solutions. Now they are building a profitable company but keeping in their DNA this end user obsession.
They are combining inner sourcing software development (led inside Databricks) with open sourcing software development (led by the community). This has led them to create powerful productivity tools for Data Engineers, Data Scientists and pretty soon for ANYONE, with the usage of GenAI. Boosting collaboration and allowing people to solve tough problems faster.
Cool projects combining ISS & OSS
Let’s start the conference debriefing by highlighting that two years ago in the DATA + AI Summit 2021 they announced the Unity Catalog, a great governance tool only available inside their platform as an inner sourcing initiative and inspired by Delta Lake the open source project. They also announced Photon, another great tool inspired by the open source project Apache Spark but a lot faster and only available inside their platform.
 Unitiy Catalog
Unitiy Catalog
Last year in DATA + AI Summit 2022 they announced Databricks Marketplace, a great tool to share data within companies and Clean rooms, another tool to make this process as secure as possible. These solutions, available only inside Databricks, were inspired by Delta Sharing, an open protocol for secure data sharing.
 Marketplace
Marketplace
This year in DATA + AI Summit 2023 they announced LakehouseIQ, a productivity tool that will democratize the usage of Databricks to anyone who knows English and is willing to ask inside the platform (as it will only be available there). To be able to use it you will first need to implement the Unity Catalog as it will learn from the data available in it. You will need to be aware that the open source version of this solution might be the English SDK for Apache Spark, a tool that will let you interact with Spark by writing down simple English commands.
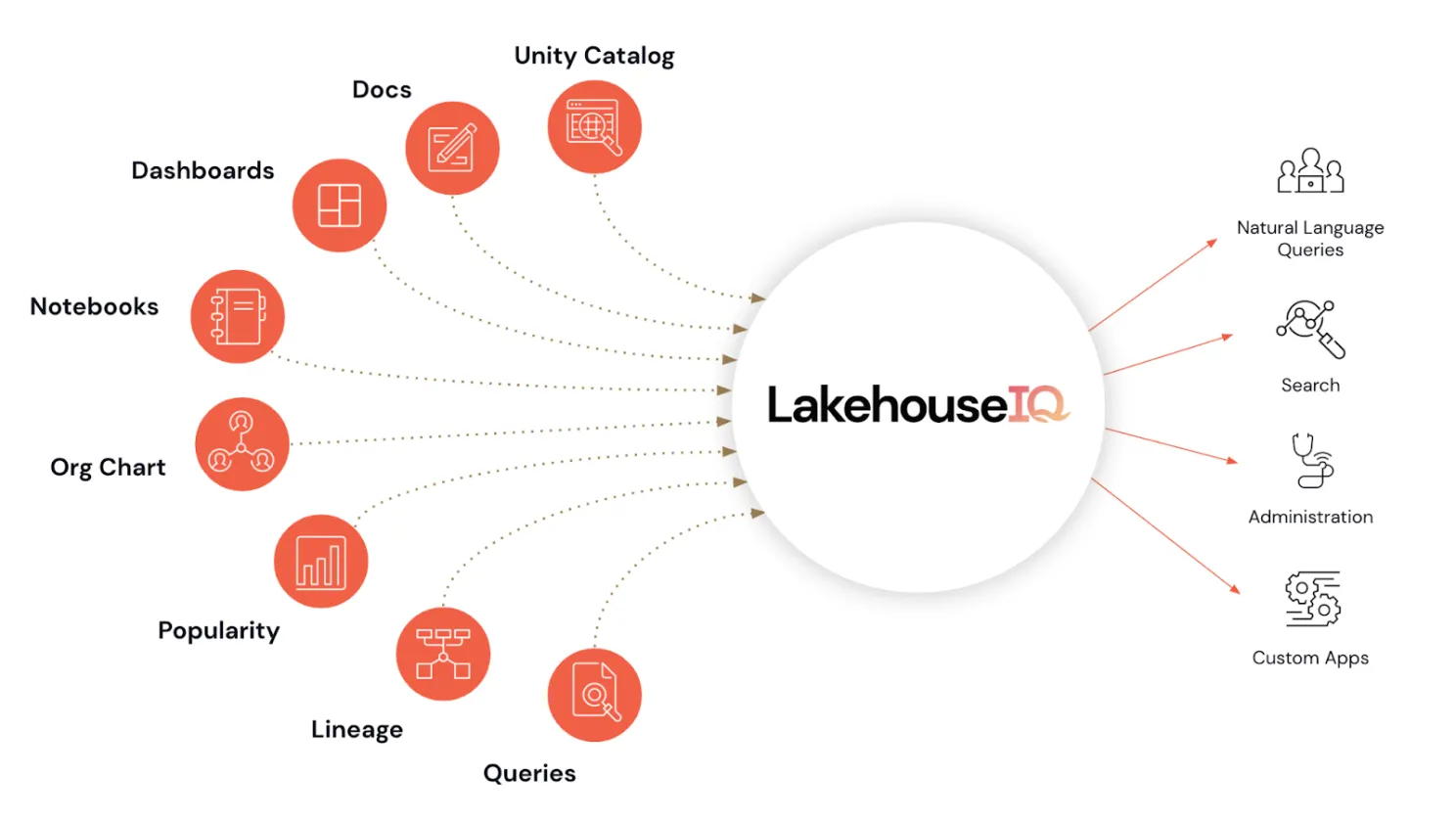 LakehouseIQ
LakehouseIQ
Now you are aware of some of their core projects and how they combine Open Sourcing with Inner Sourcing at a corporate level. In my personal opinion this is a great approach to be closer to the community and to better understand their pain points. Their biggest challenge now is to innovate even faster as this disruptive transformation with LLM’s and GenAI will change the way we interact with those platforms.
How to get the most out of this experience?
As you can imagine these are just a few of the thousands of topics covered during the DATA + AI SUMMIT. To get the most out of being in person during those days I would recommend:
Go with some colleagues to be able to participate in more conversations. Plan in advance the break out sessions and meetups you will like to participate in. Define a clear objective of why you would like to attend in person to the conference. Keynotes will be available online.
Networking
Another reason why these events are so amazing is because of the incredible people you get to meet and interact with there. Not only do you have the opportunity to work closely with colleagues who will help you lead a transformation inside your company, but to reconnect with old friends who will invite you to incredible meetups, dinners and events during the summit.
I did my list of people I admire and I had the privilege to meet:
Denny Lee author of several Apache Spark Books and the top OSS Community leader working at Databricks. Jules S. Damji author of Learning Spark, now Developer Advocate at Anyscale company behind Ray. Demetrios Brinkmann founder of the Global MLOps Community with whom I am hosting MLOps Community Bogota.
Jonathan Frankle Chief Scientist in MosaicML GenAI company recently acquired by Databricks for 1.5 billion dollars. Simon Whiteley cofounder of Advanced Analytics company and a YouTube Channel full of Apache Spark related content. Weston Hutchins one of the minds behind LakehouseIQ and Senior Staff Product Manager at Databricks. Mattew Powers, Carly Akerly, the whole Delta Lake amazing team and many other amazing people.
Attending the DATA + AI Summit 2023 in San Francisco has been a great opportunity to push my limits, to keep up to date with the latest trends in the DATA + AI landscape and to build even closer relationships with key partners.
Thank you for reading me.

 Some of the people I shared with
Some of the people I shared with
